Agibot Released the Industry First Open-Source Robot World Model Platform – Genie Envisioner
Shanghai, China, 17th Oct 2025 — Agibot has officially launched Genie Envisioner (GE), a unified world model platform for real-world robot control. Unlike traditional fragmented systems of data, training, and evaluation, GE integrates future frame prediction, policy learning, and simulation evaluation into a single closed-loop framework.
This innovation enables robots to perform end-to-end reasoning and execution — from seeing to thinking to acting — within one consistent world model. Trained on 3,000 hours of real robot data, GE-Act significantly outperforms State-of-the-Art (SOTA) methods in cross-platform generalization and long-horizon task execution. Moreover, it opens a new pathway for embodied intelligence that connects visual understanding directly to action.
Unified Video-Generative World Model
Traditionally, robot learning systems rely on separate stages — data collection, model training, and policy evaluation. However, each stage requires unique infrastructure and constant fine-tuning. Consequently, this slows down development and limits scalability.
The GE platform resolves these limitations by introducing a unified video-generative world model. It merges all stages into one efficient closed-loop system. Built on roughly 3,000 hours of real robot manipulation video data, GE maps language instructions directly to the visual space, preserving all spatial and temporal information of robot-environment interactions.

The key innovation of GE lies in its vision-centric modeling paradigm. Unlike mainstream Vision-Language-Action (VLA) systems that depend on Vision-Language Models (VLMs), GE models interaction dynamics directly within the visual space. Therefore, it retains spatial structures and temporal evolution with exceptional precision.
As a result, GE achieves more accurate and direct modeling of real-world dynamics. This paradigm brings two primary benefits.
Efficient Cross-Platform Generalization
First, GE offers powerful cross-platform generalization. Leveraging visual pre-training, GE-Act requires minimal data to adapt to new robot systems. On platforms such as Agilex Cobot Magic and Dual Franka, GE-Act successfully executed tasks after just one hour of teleoperation data — about 250 demonstrations.
In contrast, even models like π0 and GR00T, pre-trained on massive multi-embodiment datasets, failed to match this efficiency.
This advantage arises from GE-Base’s universal manipulation representations in the visual space. By modeling visual dynamics instead of linguistic abstractions, GE captures fundamental physical laws and shared manipulation patterns, allowing fast and reliable adaptation.

Accurate Execution in Long-Horizon Tasks
Second, GE’s vision-centric structure grants it powerful future spatiotemporal prediction abilities. By modeling temporal evolution explicitly, GE-Act can plan and execute tasks that demand long-term reasoning.
For instance, in complex multi-step operations like folding a cardboard box, GE-Act achieved a 76% success rate, surpassing π0’s 48% and leaving UniVLA and GR00T at 0%.
This improvement comes from GE’s innovative sparse memory module, which helps robots retain key historical information for precise contextual understanding. By predicting future visual states, GE-Act foresees the results of actions and generates smoother, more coherent manipulations. Conversely, language-based systems often suffer from error accumulation in extended sequences.

Three Integrated GE Components
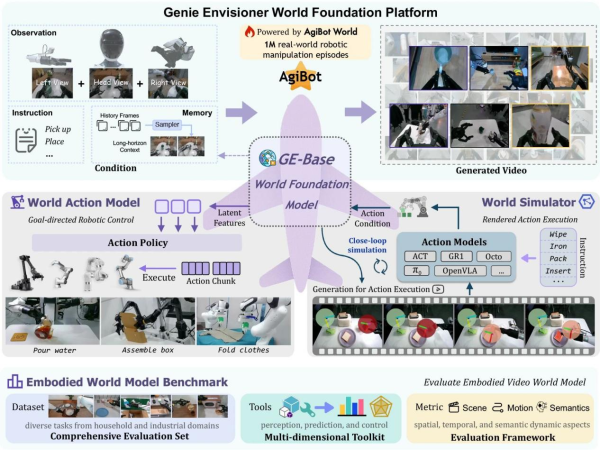
The GE platform consists of three tightly integrated components: GE-Base, GE-Act, and GE-Sim.
GE-Base: Multi-View Video World Foundation Model
GE-Base serves as the foundation. It uses an autoregressive video generation framework that divides outputs into short video segments. Its main innovations are multi-view generation and sparse memory mechanisms.
By processing visuals from three cameras — one head-mounted and two wrist-mounted — GE-Base ensures spatial consistency while capturing the complete manipulation scene. Moreover, the sparse memory mechanism supports long-term reasoning by sampling historical frames, maintaining temporal coherence for multi-minute tasks.

Training occurs in two phases. First, temporal adaptation training (GE-Base-MR) applies multi-resolution sampling between 3–30Hz to handle variable motion speeds. Then, policy alignment fine-tuning (GE-Base-LF) uses a fixed 5Hz sampling rate for downstream task alignment.

The full process took 10 days using 32 A100 GPUs on the AgiBot-World-Beta dataset, which includes 3,000 hours and over one million robot interactions.
GE-Act: Parallel Flow Matching Action Model
GE-Act operates as a plug-and-play module that converts visual latent representations into executable robot commands. With a 160M-parameter lightweight structure, it mirrors GE-Base’s architecture but uses smaller dimensions for efficiency.
Through a cross-attention mechanism, GE-Act ensures generated actions align precisely with visual and task-related cues.

Real-Time Action Model Training
GE-Act’s training unfolds in three stages. First, action pre-training maps visual representations into the policy space. Next, task-specific adaptation fine-tunes the visual model for particular objectives. Finally, action fine-tuning captures intricate control dynamics.
Notably, its asynchronous inference mode allows rapid processing: the video DiT runs at 5Hz for single-step denoising, while the action model operates at 30Hz for five-step denoising. This “slow-fast” dual-layer optimization enables 54-step inference in just 200ms on an RTX 4090 GPU, achieving smooth real-time control.

GE-Sim: Hierarchical Action-Conditioned Simulator
GE-Sim extends GE-Base’s generative capacity into an action-conditioned neural simulator. It predicts visuals accurately through a hierarchical conditioning process.
Two key features make this possible:
- Pose2Image Conditioning projects seven-degree-of-freedom end-effector poses into the image space for spatial alignment.
- Motion Vectors calculate movement between poses and encode them as motion tokens within the DiT blocks.

Together, these elements translate low-level commands into predictive visuals, allowing closed-loop evaluation. GE-Sim runs thousands of simulations per hour on distributed clusters, making large-scale policy optimization faster and more efficient.
In addition, it serves as a data engine, producing diverse training samples by re-running identical trajectories under varying visual conditions.

Advancing Vision-Centric Robot Learning
Together, GE-Base, GE-Act, and GE-Sim create a unified, vision-centric robot learning ecosystem. GE-Base models the visual world, GE-Act transforms perception into action, and GE-Sim supports policy evaluation and data creation. Collectively, they push the boundaries of embodied intelligence.
To measure quality, Agibot developed the EWMBench evaluation suite, which scores visual models based on scene consistency, trajectory accuracy, motion dynamics, and semantic alignment. Expert evaluations matched EWMBench scores, confirming its reliability. Compared with models like Kling, Hailuo, and OpenSora, GE-Base achieved the highest accuracy and alignment with human judgment.

Finally, Agibot will open-source all code, pre-trained models, and tools. With its world-model-based vision approach, GE represents a milestone — marking a shift from passive execution to active “imagine-verify-act” cycles. Moving forward, GE will integrate more sensors, support full-body mobility, and enable human-robot collaboration, accelerating intelligent manufacturing and service robotics.
Company Details
Organization: Shanghai Zhiyuan Innovation Technology Co., Ltd.
Contact Person: Jocelyn Lee
Website: https://www.zhiyuan-robot.com
Email: Send Email
City: Shanghai
Country: China
Release Id: 17102535600